 AlphaGo Lee(左)與李世乭(右)對弈轉播畫面。(圖/gogameguru.com)
AlphaGo Lee(左)與李世乭(右)對弈轉播畫面。(圖/gogameguru.com)
圍棋(GO)雖然只是由黑白兩色的棋子跟簡單的遊戲規則所組成,但玩法卻千變萬化,因此被公認為最困難的棋類遊戲之一。相較於其他的棋類遊戲,圍棋的每一步棋可以選擇的路徑更多,舉西洋棋為例,每步棋僅有20種步法,而圍棋每步棋卻高達200種,棋局的可能變化數目比全宇宙所有物質的原子總數(十的八十次方)還要多,即使出動全世界的電腦同時全力運作一百萬年,這樣運算能力也還不足以運算出所有棋局的變化。因此,對於電腦來說,圍棋是很難破解的關卡,而打敗職業棋士一直是人工智慧的一大挑戰。
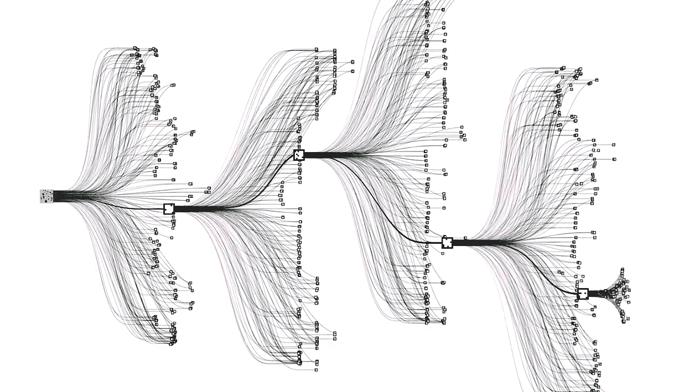 AlphaGo 預測棋局的模擬圖,透過樹狀分枝去搜尋最佳的棋步。(圖片來源:Deepmind/網址:https://deepmind.com/)
AlphaGo 預測棋局的模擬圖,透過樹狀分枝去搜尋最佳的棋步。(圖片來源:Deepmind/網址:https://deepmind.com/)
機器學習模擬人腦
如果你問一名職業棋士為何走那一步棋,有時他會回答:「因為感覺是對的。」然而,這種抽象的感覺,對於需要嚴謹邏輯推論的電腦運算來說卻有如天書般的存在。一直到了機器學習技術的快速發展,人類才得以賦予電腦這份「直覺」。機器學習的原理就是仿造人腦而建立的神經元數學模型,並利用一層層連結的結構來模擬人腦,造就一個具有學習跟歸納能力的類神經架構。
這個仿生結構的概念已經存在很久,只是到近代硬體運算能力爆炸成長後,我們才得以實現這個需要大量平行運算的架構。回首過去人工智慧運算的發展史,1997年IBM打造的超級電腦深藍(Deep Blue)擊敗了俄羅斯籍世界西洋棋棋王加里·基莫維奇·卡斯帕洛夫(Garry Kimovich Kasparov),深藍的作戰策略主要是透過計算接下來的12步所有可能發生的棋局來擊敗對手。然而,人工智慧-「AlphaGo」最初設計的目標是仿效人類的直覺,而不再是利用深藍電腦所採用的暴力解題法透過強大的計算能力來計算所有可能的棋局以打敗人類。
AlphaGo走棋的方式
AlphaGo下棋主要分成三個步驟,第一步會掃描棋子擺放情況並從中找出可行的落點,第二步從每個可行的落點建構出預測棋步的樹狀圖,第三步在對每個樹狀的分支計算勝率並找出最大獲勝機率的落點。在AlphaGo挑戰完世界棋王之後,接著又歷經了幾次升級並成為了最新版的-「AlphaGo Zero」,這個系統則不再需要透過人類進行訓練,也不再倚靠人類的知識,即為它不再需要人類的幫忙與訓練,並且也已不再僅侷限於圍棋,而是可以在各項棋類活動、競賽中大展身手。這其實也意謂著:為未來的人工智慧將有無限可能的發展。
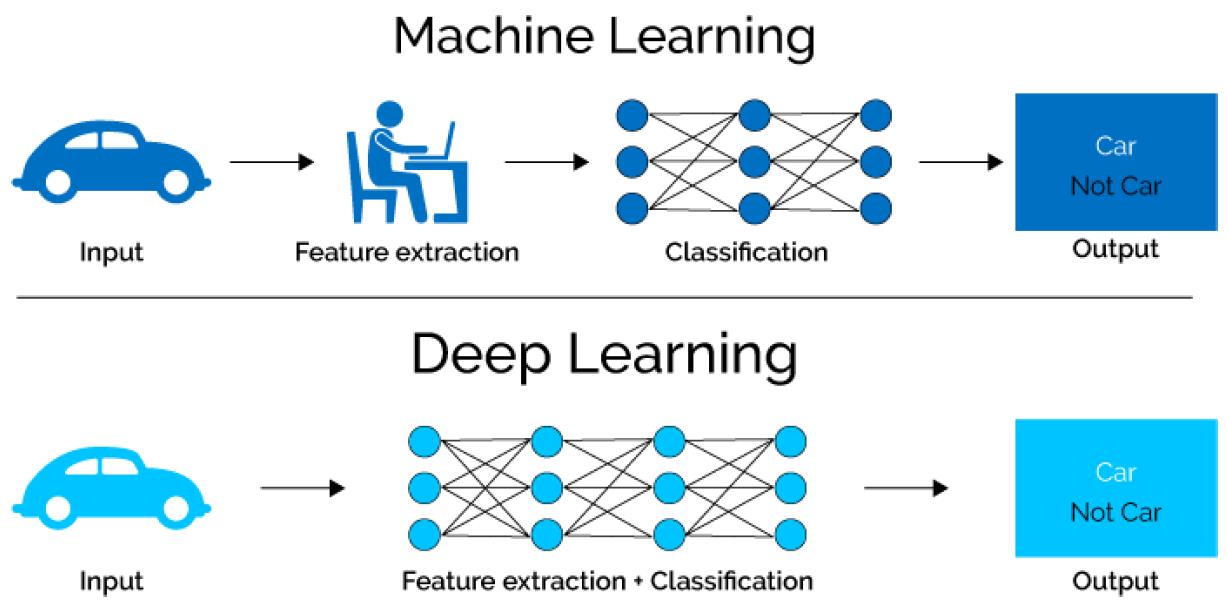 透過多層結構的類神經網路,深度學習能夠比傳統機器學習有更佳的學習跟辨識能力,甚至可以自主訓練學習,不需要人類的幫忙。(圖片來源:xenonstack/網址:https://www.xenonstack.com)
透過多層結構的類神經網路,深度學習能夠比傳統機器學習有更佳的學習跟辨識能力,甚至可以自主訓練學習,不需要人類的幫忙。(圖片來源:xenonstack/網址:https://www.xenonstack.com)
令人好奇的是,難道人類真的無法打敗這台超級電腦嗎?即使AlphaGo在2016年對戰18次世界冠軍李世乭的時候已經可以預測接下來的50步棋,但是在第四戰的時候還是輸給了職業棋士,難道機器也會出錯嗎?其實當下AlphaGo認為李世乭走那一步被譽為神之一手的機率只有萬分之一,而正是那一步棋讓AlphaGo接下來所有棋步走向崩潰,由此可知,即使AlphaGo與自己對弈了數萬局棋,仍然還是有些盲區存在。不過在Deepmind團隊持續升級AlphaGo之後,2017年AlphaGo Master對戰中國世界冠軍柯潔已經毫無懸念的取得3:0勝利了。
在接下來的文章中,我們將針對AlphaGo的演進以及其所擁有的能力及技術作介紹。在人工智慧技術日益發展並邁向成熟之路的同時,哪些部分仍有不足待解決之處,又有哪些道德以及責任需要被注意與探討的,都是人類在面對全新的智慧生活環境時所需深入思考的。透過此系列介紹,讓讀者有更多層次的思考角度。
副總編輯:國立中山大學資訊工程學系 陳坤志教授
總編輯:國立中山大學資訊工程學系 黃英哲教授
