
115/01/30
用擴增實境蓋工廠,真人版模擬城市,先從虛擬預見真實?
寒波|
科技大觀園特約編輯
臺灣大學資訊工程系陳縕儂副教授專訪
近年來因為人工智慧、大數據、區塊鍊等應用科技快速發展,以及google等科技公司大舉來到臺灣進駐並招聘大量軟體工程師,臺灣頂大的資工科系成為超熱門志願。不過大家對資工系的印象就是要學寫程式,也就是俗稱的coding,但coding在解決什麼問題?今天我們訪問了臺大資工系的陳縕儂副教授,從老師的專業「自然語言處理」(Natural Language Processing,縮寫NLP)做切入,來帶大家了解資工系究竟在解決什麼問題。
讓 AI 聽得懂人話,就是「自然語言處理」
陳縕儂老師的機器智慧與理解實驗室,主要是針對語言處理及對話系統相關技術進行研發,藉由機器學習技術,透過資料讓機器自動學習,理解人類語言並且進行適當的互動,目標是希望能讓機器的智能比肩人類,甚至超越人類。

陳縕儂老師與實驗室今年參加Amazon Alexa Prize Taskbot競賽的研究生們合影。圖/陳縕儂提供
「自然語言處理」是資工領域中的一個分支,名字聽起來很抽象,但其實這項學門的目標就是讓電腦可以「聽懂」人類說的話、「理解」語意並給予「回應」,就像鋼鐵人電影中的 AI 助理 Jarvis,鋼鐵人只要說如常說話就可以下達指令,讓 Jarvis 協助生活中各種大小事。
不過理想很飽滿現實卻很骨感,要做到像Jarvis這樣有求必應的AI助理並不容易,目前市面上的智慧助理如 Apple Siri、Google Assistant 及 Amazon Alexa 都已經隨著3C產品普及化了,但很多時候它們仍會說:「很抱歉,我聽不懂你的意思。」可見,從 Siri 到到 Jarvis 仍有很長的一段路要走,但為什麼這是條漫漫長路?——歡迎來到「自然語言處理」的思考領域。
從「聽懂」到「回應」,AI 必須克服多項關卡
大家可以想像一下,今天要跟一個 AI 互動,通常是透過語音或者文字來下達指令,接著AI就會協助我們完成特定的任務,並解決特定的問題。
在這個過程中,有四個主要的環節必須克服,分別是語音辨識 (Automatic Speech Recognition; ASR)、語意理解 (Natural Language Understanding; NLU)、對話決策 (Dialogue Management)、以及語言生成 (Natural Language Generation; NLG),說的白話一點,就是接收你講的話、翻譯成 AI 能理解的指令、要如何處理指令,以及怎麼把回應翻譯成人類能聽懂的聲音或文字。
在這四個環節裡都有相當複雜的問題需要去解決,譬如語音辨識,在技術上通常是將語音訊號直接轉換成文字,讓 AI 去理解,但在將音訊輸入的過程中,就必須要排除掉我們口語中會用的「嗯」、「啊」、「喔」等贅字或不自然的停頓,又或者是新創的流行語、方言、口音......等等的問題必須先解決,才能讓AI真的能聽懂人類的自然語言。
在「語意理解」上,要讓 AI 去分析語言或文字的脈絡、理解關鍵字,再找出對應的資料(搜尋資料庫);而「對話決策」更是困難,前面理解了人類的語言或文字表意後,AI 應該要如何回應?可能使用者給的資訊不完整,AI 要追問使用者以釐清問題?又或者在語意理解上有聽不懂的字,得要再次詢問並確認?
這還只是 AI 面對人類自然語言時,其中幾個回應的選項,真實的對話情境可能更加複雜,而且整個對話過程只要有一個環節正確度不夠高,那 AI 後續也很難準確的回應,只要有一步錯了,就會對後續對話體驗造成負面影響。
不過好消息是,現在的深度學習技術已經相當成熟,只要餵資料給電腦時,告訴他怎麼樣是對、怎麼樣是錯,基本上電腦都可以不斷修正(餵的資料也要夠多),再加上現行語言代表模型的優化,智慧 AI 在特定領域的應用上都有蠻不錯的成果。
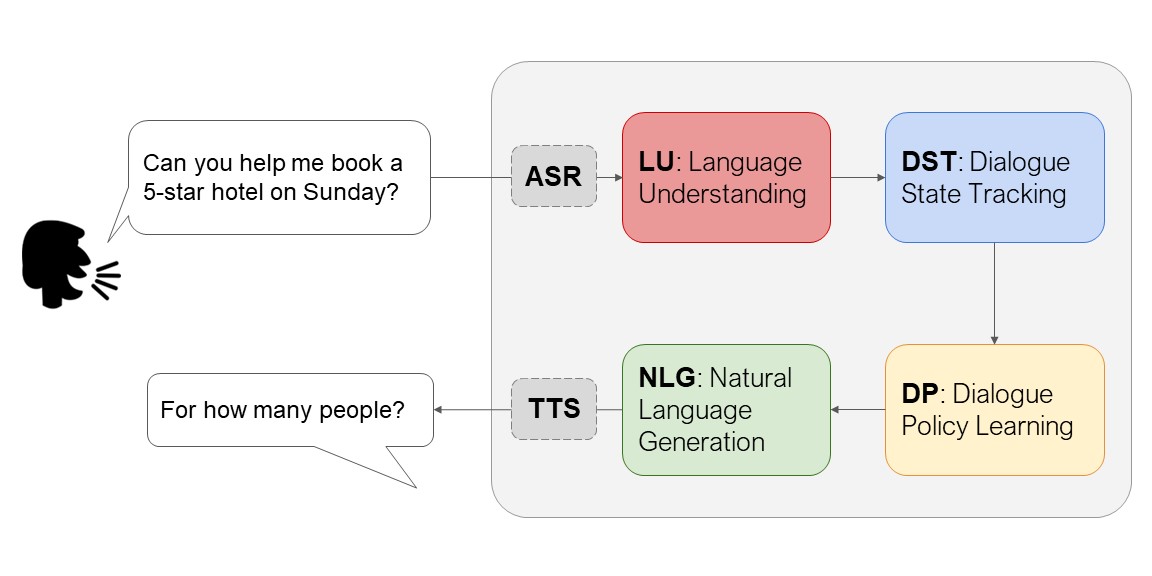
AI 處理語音指令的過程。圖/陳縕儂提供
Jarvis 仍遙遠,AI 的新突破是精準翻譯
聊到這幾年 AI 的重要突破,老師提到三年前 Google 所開發的語言代表模型 BERT(Bidirectional Encoder Representations from Transformers),當時 BERT 一出現市面上所有自然語言處理的模型都改採用了它的運作邏輯。相較於過去的語言模型,通常都是餵指定任務的文字來訓練電腦,BERT 是在給電腦任務前,先餵它吃很多的文章或書,接著再提供任務給它。以翻譯為例,這就好像讓一般人翻譯,跟讀過很多書的人來翻譯一樣,讀過很多書的人懂得字彙跟用法,自然翻譯出來的成品更流暢。
而 BERT 的技術確實也得到相當好的成效,所以擊敗了當時許多正在開發的語言模型,成為了當前語言模型的基礎。有趣的是,BERT 的前身是一個名為 ELMo(Embeddings from Language Models,與芝麻街角色名字相同)的語言模型,所以 BERT 的開發者們就用芝麻街的角色,來為他們開發出來的語言模型命名。
當前 AI 發展的目標,為它建立「人的常識」
雖然說 NLP 領域在商業與學術上都有相當大的發展空間,但陳老師認為,目前要達到人的「common sense(常識)」對AI來說還是非常困難,舉例來說,今天我們跟智慧助理說我今天要跟某某人吃晚餐,這個時候如果是人類的助理,我們可能會聯想到「吃什麼」、「要不要聯絡某某人」、「交通方式是?」......等等與飯局相關的問題,但AI目前並沒有辦法執行這麼複雜的互動,還得必須跟 AI 說「幫我訂位」、「幫我叫車」,仍在一個指令一個動作的狀態,這種 AI「common sense」的建立,可說是目前非常有挑戰性的項目。
AI 的開發方向——人類的工作輔具
身為 AI 的設計者,陳縕儂老師認為 AI 會成為輔助人類的一部分,雖然說現階段許多人對於 AI 可以執行我們的工作感到彆扭,但實際上 AI 正在減輕我們的工作量,舉例來說,像是目前醫院已經有在使用協助診斷的 AI,但這樣的 AI 並不會取代醫生的工作,因為AI只是提供醫生診斷的相關依據,實務上對於病患的判斷最終還是得由醫生來做。
雖然 AI 已在產業中被廣泛利用,但基本上仍以「人機協作」為大宗,雖然能取代部分人力,但像是創造類型的工作 AI 就幾乎無法獨自完成。至於大家想像中,AI 恐對人類造成威脅的情節,基本上不會發生,因為 AI 是不會憑空出現意識的,AI 威脅人類的可能,比較會是人類不當利用造成的風險,所以在未來 AI 的開發上,基本上會往輔助人類的方向去做應用。

身為 AI 的設計者,陳縕儂老師認為 AI 會成為輔助人類的一部分。圖/Pixabay
資工領域瞬息萬變,「喜歡新知」很關鍵
談到什麼特質適合來讀資工系,陳縕儂老師認為,數學或是邏輯只是基礎,重要的是「喜歡接受新知」的特質,因為在資工領域瞬息萬變,資訊更新的相當快速,隨時都會有新東西出來,如果不喜歡吸收新知識,讀資工系可能會比較痛苦一點。另外,資工在應用上時常會和不同領域的人做合作,你必須了解對方的需求跟他們的條件,才能設計出能夠幫別人解決問題的方法,而這也是資工有趣的地方。
陳縕儂老師也和我們分享了在他眼中臺灣學生和外國學生的差異,他認為臺灣學生應用網路資源自學的能力非常強,而外國學生則是勇於在課堂上和老師提問並討論,各有各的優點,不過教授也認為由於臺灣學生擅長自己找答案,所以在協作與表達上的可能相較於外國會比較弱一些,但如果這一塊能做到加強,臺灣的學生其實是非常有競爭力的。

陳縕儂副教授認為,臺灣學生在協作與表達上相較於外國學生較弱一些,但若能加強這一塊能力,臺灣學生非常有競爭力。圖/呂元弘攝
最後老師還告訴我們,當初大學時機器學習與 NLP 領域並不是資工領域的主流,一開始只是選擇了自己有興趣的領域,也沒想到近幾年 NLP 會變成現在的顯學,他認為自己真的非常幸運,可以一路延續自己熱愛的主題。
最後的最後,陳縕儂老師建議有意投入資工領域的學員們,可以先了解這個領域需要的先備知識,像是 coding 要用到的程式語言、跟 AI 相關的內容則會牽涉到數學,最後當然就是對知識的熱情和態度,了解之後才比較能判斷這個領域適不適合你,千萬不要因為從眾而選擇。
 姓名標示─非商業性─禁止改作
姓名標示─非商業性─禁止改作
本著作係採用 創用 CC 姓名標示─非商業性─禁止改作 3.0 台灣 授權條款 授權.
本授權條款允許使用者重製、散布、傳輸著作,但不得為商業目的之使用,亦不得修改該著作。 使用時必須按照著作人指定的方式表彰其姓名。
閱讀授權標章或
授權條款法律文字。