自2001年Google推出線上翻譯系統以來,該系統從原本僅能翻9種語言,進步到能翻103種語言。以前常常發生的詞語排列不合文法和歧義理解有誤等問題,如今也藉著採用新的翻譯系統而多有改善。現在,Google翻譯每日要翻譯1400億以上的單字,並服務數百萬的用戶。
究竟Google翻譯是如何運作,又進行了什麼改革,才有如此出色的能力?Google翻譯又是否真的已經可以取代有血有肉的翻譯員?以下便針對Google翻譯的系統沿革和優缺點,進行簡單的說明。
Google翻譯的基礎和早期系統架構:機器學習和片語式機器翻譯
Google翻譯是以機器學習(machine learning)為基礎來應付語言的複雜多變。機器學習多運用在人工智慧上,指機器從已知資料中分析出規律,再把規律套用在新資料上,並在不斷套用的過程中提高效率或進行修正。藉著機器學習,Google翻譯讓電腦自己找出不同語言的文法規則,省下慢慢教電腦文法的麻煩。
學會文法後,接下來就面臨翻譯正確性的問題。早期的Google翻譯要翻譯句子時,會先將原文拆成單字或片語,接著利用統計學和Google收集的大量現存翻譯資料,分別選出這些單字片語最普遍的譯法,再依照文法重組成句子。這種類似逐字翻譯的演算法,稱作片語式機器翻譯(phrase-based machine translation,以下簡稱PBMT)。
PBMT即使是當時先進的機器翻譯系統,但免不了許多缺點。首先,統計出來最有可能的翻譯,有時不是最正確的。比方說,假如大多數資料把took off譯作「起飛」,Google翻譯便很有可能把I took off my clothes(我脫掉我的衣服)譯作「我起飛我的衣服」。其次,PBMT以翻譯單字片語為主,翻譯句子的能力有其極限。當句子長、結構複雜、有歧義(ambiguity)或是有文法上的例外的時候,PBMT便容易翻錯。最後,若沒有某兩種語言的直接互譯資料,PBMT必須透過多次轉譯,才能翻譯完成,而這個過程使得效率和翻譯的正確性大打折扣。
由於有這些缺點,加上Google翻譯的資料庫以英文為主(不論是原文或譯文),當翻譯資料稀少或遇到和英文文法差異大的語言時,Google翻譯的出錯率就會升高。為了翻得更快更好,Google翻譯的改進勢在必行。
Google 翻譯大革新:神經機器翻譯和零數據翻譯
約在採用PBMT系統10年後,Google翻譯於2016年宣布今後會以神經機器翻譯(Google Neural Machine Translation system,以下簡稱GNMT)取代PBMT,並聲稱翻譯會變得更準確、通順。
GNMT的特色是以句子為單位進行翻譯。翻譯句子時,它會將句中每個字編碼成向量,該向量代表著這個字和它之前所有字合在一起的意思。比方說,句子裡第三個字的向量代表第一、第二個字和它自己本身合起來的意義。這個含意是系統才可以解讀的,而非人類可以理解。等到該句的向量全部被編碼出來,GNMT會再進行解碼。每次解碼不會只針對一個向量,而是會連其餘向量都一起納入考量,以生成對應的翻譯。總結來說,比起把句子拆成單字後獨立翻譯的PBMT,GNMT更加重視句子的結構和字詞間的關係,能更正確的分析全句意義再進行翻譯。
Google翻譯聲稱,採用GNMT後,幾個主要語言的翻錯率降低了55%到58%。除此之外,在2016年時的翻譯測驗裡,評分員給了GNMT接近人類譯者的分數。以上事例皆顯示GNMT比PBMT有更佳的表現,甚至可說是非常「人類」。
 人類、GNMT和PBMT的翻譯對照 (圖片來源:Google Research Blog)
人類、GNMT和PBMT的翻譯對照 (圖片來源:Google Research Blog)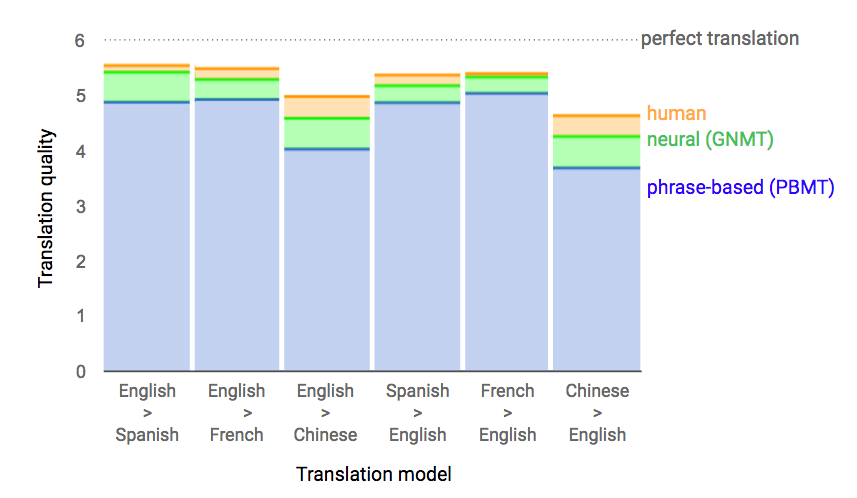
人類評分員評比人類、GNMT和PBMT的翻譯質量後的分數表。分數從最低分0分到滿分6分,代表從「無意義的亂翻」到「完美的翻譯」。( 圖片來源:Google Research Blog)另外,Google翻譯的團隊還發現,對GNMT進行改良後,GNMT便能在沒有A語言和B語言互譯資料的情況下進行該兩種語言的直接翻譯,也就是實現零數據翻譯(zero-shot translation)。這是以往依賴統計資料的PBMT所難以達成的。
Google翻譯是如何做到零數據翻譯的?先前有提到,GNMT會把句子編碼成向量。由於向量代表句子的含意,而同一句話幾乎不會因為語言不同而改變太大的意思,因此理論上不同語言的同一句話會擁有相近的向量。Google翻譯改良GNMT時,讓兩種語言互譯的翻譯知識(translation knowledge)能在翻譯其他語言時作為參考。如此一來,GNMT能有效率的掌握同一句話在不同語言間的向量,並迅速找到相對應的譯文。舉例來說,如果Google翻譯有同一句話英文翻成韓文和英文翻成日文的資料,想要進行它從沒做過的日韓翻譯時,只要有了該句日文版本的向量,它便能很快地找到數據相近的韓文版本的向量,期間完全不用轉譯成英文。這使得GNMT在翻譯效率和正確性兩方面都勝出早期的PBMT。
Google翻譯取代人類翻譯?
面對翻譯水準大大提升的Google翻譯,以翻譯為生的人可能會擔心丟了飯碗。其實,現今的Google翻譯依然有不足之處。比方說,它會漏字、不太會翻少見的用語或法律條文之類複雜的文體,也沒有辦法翻得像人類一樣有「詩意」或斟酌譯文的語氣和風格等。Google翻譯也主張,它以翻譯日常用語為主,必要時還是要聘用專業的翻譯家比較好。由此可知,Google翻譯要取代活生生的翻譯家,恐怕還是很難。不過,Google翻譯作出的革新,無疑令人印象深刻,也讓人對未來機器翻譯的進步充滿期待。
(本文由科技部補助「新媒體科普傳播實作計畫」執行團隊撰稿)
