 人工智慧AlphaGo憑藉深度學習技術,於2016年打敗世界棋王李世乭,一戰打響人工智慧的名號。(圖/Pixabay。)
人工智慧AlphaGo憑藉深度學習技術,於2016年打敗世界棋王李世乭,一戰打響人工智慧的名號。(圖/Pixabay。)
1950年科學家發明了電腦,此後,科學家便有一個偉大的目標,即為-利用電腦來模仿人類的思考方式,又稱為人工智慧(AI),但礙於當時的硬體技術並不足以提供人工智慧邁向更深入的研究。直到1980年科學家發展了機器學習理論,利用了許多數學的理論讓電腦能透過人類所提供的資料達到機器自我學習的目的,人工智慧-「AlphaGo」就是利用電腦透過大量棋譜的輸入,並用名為類神經網路(Neural Network)的方法來做到自行學習的機器學習技術。
類神經網路是機器學習裡面的其中一種模型,當時的學者研究發現:類神經網路模型會因為神經元層數的增加,而導致神經網路運算失真,這也是類神經網路模型在發展的過程中所遭遇到的瓶頸,無奈於此難題無法被完善的調整與解決,很快地,類神經網路的發展就漸漸沉寂了。慶幸的是,這個難題終於在2006年獲得了解決,由神經網路之父Geffory Hinton成功開發出經由多層神經網路組成的架構,即為目前大眾所熟知的「深度學習」。AlphaGo就是利用了機器學習的類神經網路和深度學習的技術達到現今幾乎無人能敵的人工智慧。
深度學習能自動抓取特徵
深度學習就像是人類腦部神經網路一樣,它可以連接到很多層神經元,並模擬神經細胞的行為,每個神經元像是各個不同的運算式,將每一個神經元的訊號,往下一個神經元傳遞,最後找到預測結果,透過此種方式來找出特徵。舉例來說,科學家要如何讓電腦辨認出這是一隻狗呢?我們人需要透過狗耳朵、狗鼻子、狗眼睛等屬於狗的特徵來分辨出該動物是一隻狗,而深度學習技術正是讓電腦透過演算法來找出這些屬於狗的特徵。在傳統的機器學習中,科學家要找出資料的特徵必須透過各領域專家的專業知識幫忙,並經過許多的研究和分析同時利用演算法方能找出代表資料的特徵,才能把這些有用及抽絲剝繭後所獲得的特徵用來作為判斷的結果。深度學習則不同在於它具有自動抓取特徵的能力,因此,可以說深度學習技術比傳統的機器學習更具人性化。
 人類腦部神經網路示意圖。(圖/Pixabay)
人類腦部神經網路示意圖。(圖/Pixabay)
一探AlphaGo的致勝關鍵
在架構上AlphaGo具有兩個獨立的網路大腦,分別稱為:(1)Policy Networks(走棋網路)和(2)Value Networks(估值網路)。在這兩個大腦的合作下可以優化電腦下棋的程式,並利用反覆的運算和結果來修正參數,使得具有人工智慧的電腦在下棋的過程中實力越來越提升。走棋網路主要為透過監督式學習的神經網路,監督式學習就是當資料輸入給電腦時,我們會告訴電腦這筆資料是什麼,舉例來說,當我們第一次看到小狗的時候,我們不知道這是小狗,需當別人告訴我們這是小狗以後,我們即有對「小狗」產生認知。相同的概念,走棋網路透過觀察棋盤然後找到最佳的下一步,並預測對手最有可能走的下一步棋。要訓練人工智慧擁有這項能力,則必須輸入大量的棋譜給電腦作為判斷的依據,去預測對手下一步最有可能落子的位置。在2016年AlphaGo成功預測的準確率是57%,為了再提升準確率,AlphaGo在走棋網路裡又增加一個增強走棋網路的技術,增強走棋網路是利用部分的樣本資料先訓練出一個較簡易的走棋網路,另一邊則使用較完整的樣本資料產生較高階走棋網路,之後讓兩個不同的走棋網路互相下棋,由於簡易的走棋網路可以從中學習到高階走棋網路的數據,進而又產生一個增強版,這個增強版會比原高階走棋網路更加進階,然後以此循環修正,就可以用來提升預測對手落子的準確率。
走棋網路和估值網路是相輔相成的關係,透過走棋網路算出對手棋子要落的位置,再透過估值網路算出勝率有多少。估值網路的主要功能就是預測每一個棋手贏棋的機率,並計算出每落一個子後,每個棋手最後的勝率是多少,這個計算出來的數字是一個近似解,如果要算出精確解答會花費太多的時間,所以我們才稱它為估值網路。但是,隨後科學家便發現估值網路有些許問題需要釐清,例如:獲得出勝率的結果是否會受到雙方實力不同而有所影響?為釐清此疑慮,科學家們利用兩台一樣的AlphaGo來互相比賽,那麼輸贏就跟兩人實力沒關係,而是跟下棋時走棋的位置有關。透過該自學方式,科學家就成功地提升估值網路預測勝率的準確度了。
AlphaGo最後的殺手鐧技術則是使用了蒙地卡羅搜尋樹(Monte Carlo tree search),來搜尋前述走棋網路和估值網路的最佳計算最佳解答。蒙地卡羅搜尋樹分為4個步驟:「選取」、「展開」、「評估」以及「倒傳導」,「選取」就是選擇幾種對手可能會落棋的位置;「展開」則是根據對手落棋的位置,找出勝率最大的落子方式;「評估」則是將行動後的棋局放到估值網路做勝率的判斷;「倒傳導」即為當AlphaGo決定最佳位置後,快速地透過走棋網路預測對手未來的走棋法,並對其再做出評估。透過上述的技術,AlphaGo就在許多科學家的努力下誕生了,成為目前為止戰無不勝、攻無不克的世界棋王!
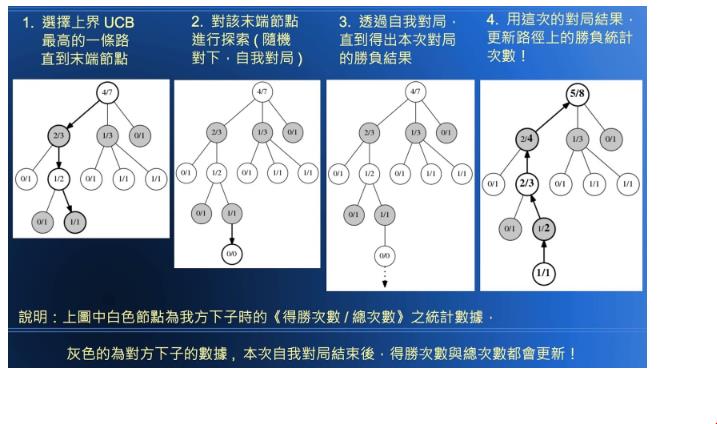 蒙地卡羅對局搜尋法的計算邏輯。(圖/國立金門大學陳鍾誠老師簡報)
蒙地卡羅對局搜尋法的計算邏輯。(圖/國立金門大學陳鍾誠老師簡報)
副總編輯:國立中山大學資訊工程學系 陳坤志教授
