
115/03/31
聊天、繪圖、語音對話的背後:揭開 AI 晶片與「龐大算力」的真面目
曾繁安|
科技大觀園特約編輯
在中央研究院資訊科學所中,有一好玩的「自然語言處理與情感分析實驗室」(NLPSA Lab),主持人為古倫維博士,主要研究主觀資訊,包括意見、情緒、使用者喜好等的處理、理解、應用與生成。目前研究方向包括:情感分析、謊言偵測、知識庫問答與文字生成、推薦系統、看圖說故事、假新聞干預等。由於篇幅有限,本篇文章帶我們特別來了解「看圖說故事」這部分。
怎麼讓電腦自動看圖說故事?
研究中為電腦所設計的看圖說故事任務有個標準:會給定有序的五張照片,根據這五張照片排列的順序,生成最後完整的故事。故事具有順序性,因此,就算拿到相同的照片,一旦順序不同,便會生成不一樣的故事。
讓電腦執行「看圖說故事」並非簡單的端對端任務(直接將圖轉成文字,只需提出圖片中有的成分),因為這樣的方式有一些天然的缺陷,也就是模型如何轉成文字我們無法完全了解,也無法在過程中控制或修改。看圖說故事比端對端更為進階了,需要適度地加入想像力,將前因後果連結起來,成為合理而有趣的劇情,才能被稱為一個「故事」。
目前除了直接請人比較評估哪個故事好之外,大家所認定一個好的故事也可以具體一點從六個角度來評估,包括以下:
研究團隊訓練電腦看圖說故事會經過兩階段:先從圖片抽取語意,即從個別圖片中選出用來說故事的元素,接著再生成文字故事,模擬真人在生成故事的時候的過程,會先理解、規劃、連結,而後再產生最後的故事(藉知識庫找出元素之間的關係,建立圖片的關聯,再為這些圖片擬定最好故事的草稿(如同電影故事大綱))。
圖片抽取語意與故事生成
抽取語意的過程,就像是為劇本「選角」,我們的模型會針對連續圖片,先以機器學習的結果,找出最適合說故事的「角色組合」,這就好比替偶像劇找到最佳的男女主角及配角卡司,主角對了,生成的故事就會比較精彩。在這個階段,若是抽取出來的元素不令人滿意,我們的模型在這個階段可以提供「換角」的功能,讓使用者指定增加、減少、或者修改使用的元素,如此一來能讓使用者了解為什麼最後會生成這樣的文本,也就是提供了所謂「可解釋性 AI」的功能,同時還能讓使用者從中間過程就改變文本內容,比起直接從影像生成最後文本,使用者能控制的程度是提高也更廣。
來舉個例子吧!
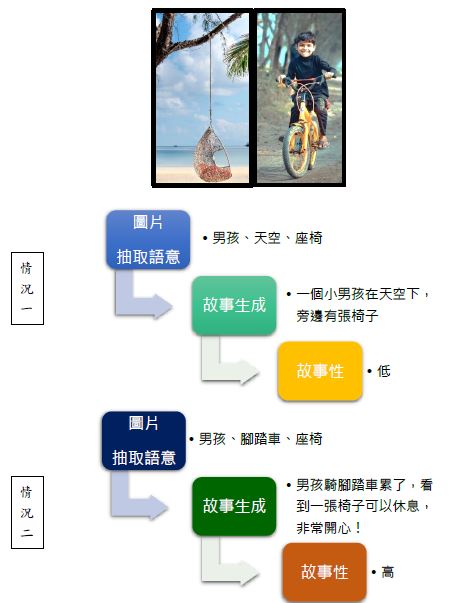
圖一:圖片抽取語意與故事生成之範例。圖/Pexels
故事中的「想像力」從何而來?
除了為故事找到最佳的主角,另外也需要適度的加入想像力,但是電腦自己很難憑空產生子虛烏有的東西,如果我們讓它知道各種知識,並且把這些知識適當地加入故事中,看起來就會像是電腦有了想像力!例如,圖片中有一隻巨龍,加上「龍會噴火」這個知識,電腦就能在看到這張照片時,說出「巨龍就要噴火了」這樣的句子。當然若是看過大量的故事,也可能學習到這個知識,但是直接提供知識給模型,便能夠縮短這個學習的過程。
為了讓模型有更多的知識,我們使用「知識庫」來幫助模型。甚麼是知識庫呢?知識庫就是將真實世界的知識,轉化成電腦能讀得懂的資訊的一種資料庫。將真實世界的知識表達出來最簡單的方法,就是描述物與物之間的關係,因此,知識庫裡的每一條知識,都使用「物、關係、物」這樣的格式來表達。這樣的資料越多,則此知識庫包含的知識也越多。
故事的連貫性?
知識庫不僅讓模型具有憑空添加內容的能力,這樣的能力亦能讓模型更好地連結圖片,產生上下文一致的故事。換句話說,找出個別圖片概念之間的關聯,說出的故事會比較連貫,具有因果關係。為了讓大家更好理解,我們來看看下面的範例:
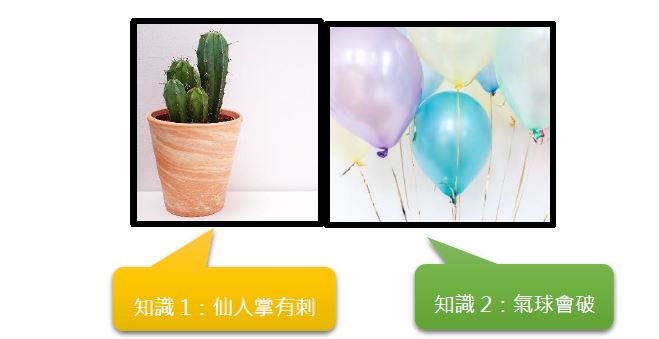
圖二:藉知識庫提升故事連貫性之範例。圖/Pexels
兩張圖片加上兩個相關聯的知識,讓電腦能自動生成「一顆氣球被仙人掌刺破了」這樣的劇情,是不是很有趣呢!
分成「語意抽取」與「文本生成」兩階段生成故事的方法還有一個優點,就是可以利用大量的「圖片辨識物件」與「故事文本」資料庫,而不一定要使用圖片與故事搭配的資料,就能夠讓電腦學會如何看圖說故事。比起圖片與故事搭配的資料,圖片辨識物件的資料與技術,在影像辨識的領域中,已經非常成熟;而純粹的文字故事,我們在網路上也隨手可得,因此有了如此大量的資料,模型學習的效果又能夠得到很大的提升,可說是一舉兩得!
若使用一般生活的照片也可以自動生成故事嗎?
依據下面圖三所列的五張照片,系統生成的故事如下:孩子們好開心,派對裡面還有南瓜,女孩們都想要一起玩,有好多好多的萬聖節服裝,有一些孩子特別喜歡跟另一些孩子一起玩,孩子們炫耀著他們的萬聖節服裝。

圖三:以照片作為故事素材之範例。圖/VIST公開語料庫
這個故事在產生的時候特別具挑戰性,因為它只是許多合照的集錦,卻要講出一個故事來!雖然如此,由所生成的故事內容可以看出系統成功地選出了一些特別能夠串連成故事的成分,漂亮地完成此任務。
未來展望
教會看圖說故事這個技術除了能自動為我們生成故事性的文本外,還有一個未來可能非常有價值的應用,就是幫助機器人對目前環境有所認識。機器人的視覺,也是由攝影機所拍攝的影像,可視為一連串的照片。當機器人看到這些照片的時候,看圖說故事技術就能自動生成一個情境描述,並且加上想像力,推測出目前狀況。圖四所呈現的是一個居家機器人經攝影機眼看到的環境,相對應生成的故事為:這裡有一個新房子,但是床很舊,一位女士正在拍攝它的照片,一位男士過來接這位女士,這位女士非常高興。根據這個故事,機器人就可以自動開啟與主人的對話,例如詢問「你想換床嗎?」、「你在照甚麼?」或是「你要回家了嗎?」等等。這也是文章標題所說的,不只「察主人言」,還要「觀四周色」,真正建構出一個能關心照護人類的暖心機器人!

圖四:應用於居家機器人之範例。圖/台灣大學資訊工程系智慧型機器人及自動化實驗室提供
除了居家機器人的應用之外,讓電腦系統「看圖說故事」的技術還可再將觸角擴展至新聞稿、廣告、童書繪本等;若是結合視覺的對話系統,便可運用於陪伴/照護機器人以及車用機器人等等,是不是很神奇又有趣呀!相信往後能展開更多令人驚豔的可能性!
 姓名標示─非商業性─禁止改作
姓名標示─非商業性─禁止改作
本著作係採用 創用 CC 姓名標示─非商業性─禁止改作 3.0 台灣 授權條款 授權.
本授權條款允許使用者重製、散布、傳輸著作,但不得為商業目的之使用,亦不得修改該著作。 使用時必須按照著作人指定的方式表彰其姓名。
閱讀授權標章或
授權條款法律文字。