
115/01/30
如果有一個「虛擬的你」,那麼你的生活,將會發生什麼事情?
陳彥諺|
科技大觀園特約編輯
 李祈均團隊開發的AI情緒辨識技術,可能在未來應用於「AI面試官」判讀面試者的情緒與個性。(圖/fatcat11繪)
李祈均團隊開發的AI情緒辨識技術,可能在未來應用於「AI面試官」判讀面試者的情緒與個性。(圖/fatcat11繪)打開情緒辨識的黑盒子
回到情緒辨識的起點,「情感運算」這個詞從1995年就由MIT的教授羅莎琳.皮卡德(Rosalind Picard)提出。當情緒產生變化時,人類也會有生理上的反應,等到訊號量測、處理的技術發展得更成熟,人們自然就將這些技術連結起來思考:是不是可以透過偵測生理訊號的變化,來辨識情緒?
情緒辨識的處理架構,包括資料收集、資料標記、資料輸入、機器學習、辨識輸出等階段。「以前很多技術是功能性的,會產生明確的結果,例如打電話聲音轉文字,這是自動語音辨識的技術;文字裡面說了什麼,這是自然語言處理(Natural Language Processing,NLP)的技術。我們轉個彎去想,情緒跟這些東西有關,做完自動語音辨識、NLP分析,是不是可以多分析一點內在的狀態?技術整合就會出現。」李祈均所投入的多模態情緒辨識,也就是透過整合語音(如說話的音高、語調)、文字、臉部表情等資訊,透過深度神經網絡分析,進行情緒的判讀。
把個性「算」出來!
人類情緒複雜,性別、年齡、個性、生活背景、乃至不同的互動情境都會影響,但過去情緒辨識無法具體評估個體差異在其中所造成的影響,讓辨識結果不夠精確。
 榮獲2019年未來科技突獎的李祈均副教授,發展出目前獲得最佳準確率的情緒辨識技術。(圖/林妤庭攝)
榮獲2019年未來科技突獎的李祈均副教授,發展出目前獲得最佳準確率的情緒辨識技術。(圖/林妤庭攝)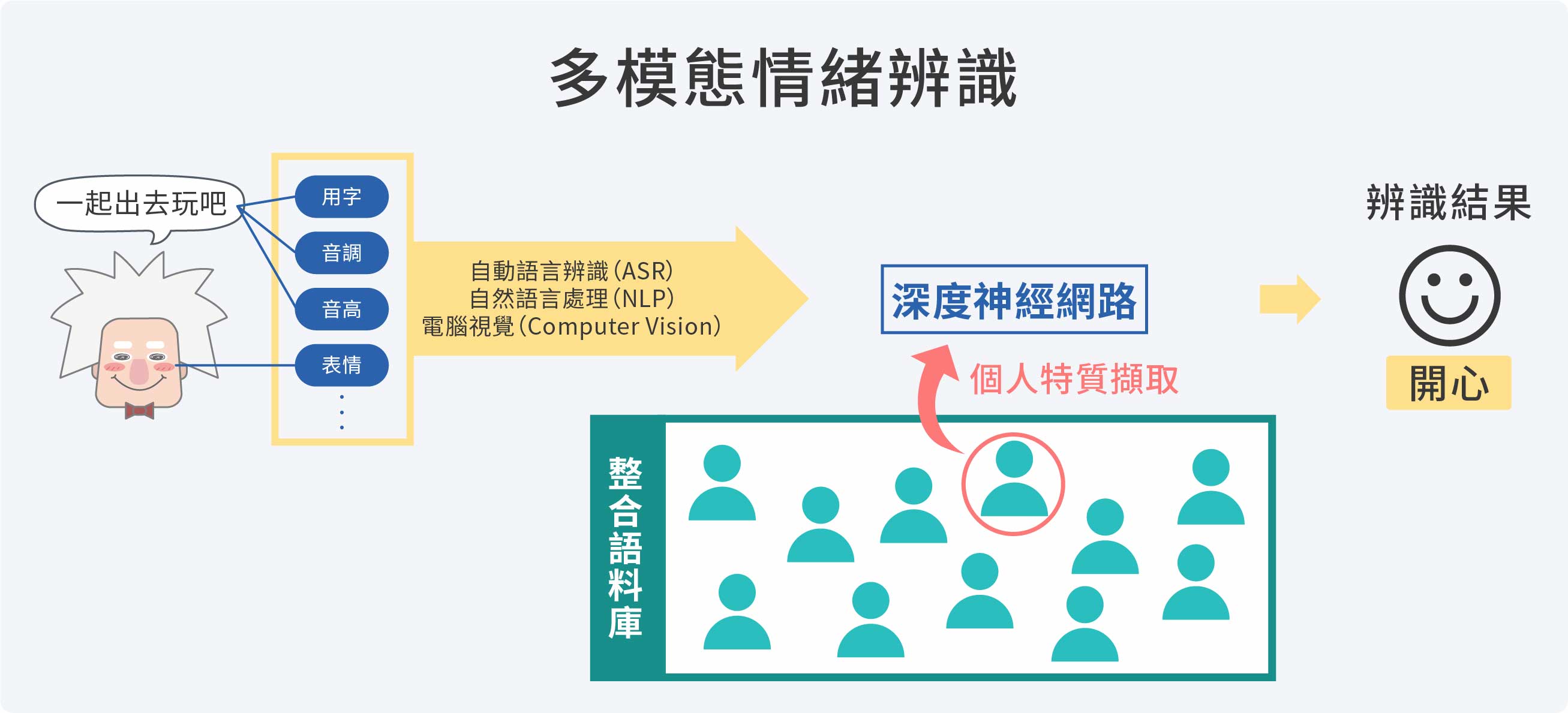 嵌入個人特質的情緒辨識技術示意圖解。(圖/沈佩泠繪,資料來源:李祈均)
嵌入個人特質的情緒辨識技術示意圖解。(圖/沈佩泠繪,資料來源:李祈均)
「以前想要知道個體差異會如何影響情緒表達,會需要將資料依照性別、年齡、種族等特徵分組,但資料分割地越細,訓練一組模型的資料就會越少,結果就變不準,這是一個很大的問題。」李祈均的個人化技術反向思考,以遷移學習繞過個性標記的瓶頸,利用機器學習一窺個體差異的端倪,為情緒辨識在缺乏個性標記的實際應用,開啟了新的可能。
懂得跨界整合,資料便無處不在
要進行情緒辨識的技術開發,需要的不只是工程方面的專業知識,其實還需要不斷摒除成見,並發揮敏銳的觀察力找到創意的突破點。以李祈均團隊2017年釋出的中文情緒互動多模態語料庫(NTHU-NTUA Chinese Interactive Multimodal Emotion Corpus,NNIME)為例,最特別的地方便在於和國立臺灣藝術大學合作,收集情緒資料。
「戲劇表演可以呈現很強的情緒張力,」李祈均表示,為了在鏡頭前捕捉最自然的情緒反應,同時擴大資料收集的效率,設計互動情境請專業演員演出,並進行錄影,是目前學界常見收集資料的方法。不過中間涉及許多專業的表演知識,導演如何訓練演員?要如何設計情境才能獲得最接近現實的情緒反應?「每多解一個小問題,就會有人提出更多的問題,也讓我多懂一點人,這個過程很有趣!」李祈均說。
情緒辨識研究,還可以如何突破?「有經驗之後,有些工具會讓標記速度變快,收集資料反而最難。」李祈均驚訝地發現,其實有很多既有資料可以多加利用。例如企業管理研究的學者探討組織溝通的行為,過程中本來就會錄下大量3到4個人的即時互動過程,「國際上公開資料庫釋出3到4人的互動資料,大約是28組,不過接觸臺大企管系後發現,他們手上的資料,近兩年累積下來,已經有90幾組!」
這樣的速度與規模讓他非常驚豔,原本收集資料是情緒辨識研究最困難的一道關卡,李祈均認為,透過跨領域的整合,把其他學科對於人類行為的研究資料挖掘出來進行工程分析,有機會快步提升臺灣情緒辨識技術開發的腳步。
情緒辨識技術的開發若要突破,最終還是要仰賴對於「人」的理解,並將技術落實到日常生活,解決「人」的問題。無論是學界或企業,臺灣各個領域都有非常優秀的專家,研究過程潛藏著無數人類互動的資料,只要工程端加以規模化,就能創造出不同價值。李祈均期待未來能有更多跨領域人才願意投入這個領域,在跨域整合下碰撞出更多新的創意火花。
 姓名標示─非商業性─禁止改作
姓名標示─非商業性─禁止改作
本著作係採用 創用 CC 姓名標示─非商業性─禁止改作 3.0 台灣 授權條款 授權.
本授權條款允許使用者重製、散布、傳輸著作,但不得為商業目的之使用,亦不得修改該著作。 使用時必須按照著作人指定的方式表彰其姓名。
閱讀授權標章或
授權條款法律文字。