自動駕駛是現在非常熱門的話題,但要讓自動駕駛成真,需要搭配很多感測周圍情況的設備,才能夠讓自駕車安全上路,而在本篇文章中,我們主要是介紹自駕車的影像自動辨識系統,在透過video cameras得到車前影像後,該如何利用這些影像資料來進行機器學習,進而辨識出道路上的物件,以保障行車的安全。
影像辨識的技術基本的需求就是希望能夠從影像中,自動找出你想要辨識出的物件,在自駕車的應用上,為了達到自動駕駛的目的以及保護在道路上行車的安全,我們無非就是希望從影像中自動判斷出是否有出現行人或前車等物件。
然而從影像中自動辨別物件的方法有很多種,如過去許多經典的影像處理方法,分析並比較照片中的某些特徵,但這些傳統的影像辨識方法,發展上一直有錯誤率過高的瓶頸,直到機器深度學習的出現,也就是現在最熱門的AI人工智慧,才徹底改善了物件辨識率過低的這個問題。
讓機器越學越聰明的深度學習
機器學習通常可以這樣定義:「從過往的資料和經驗中學習與訓練,最後達到自主判斷或預測結果的目標。」,也就是它可以替未曾見過的圖像做辨識,並預測這個新圖像可能是什麼。
機器學習又分成很多類型,在圖像辨識上,我們常使用的是監督式學習,監督式學習其實就是要先提供問題以及正確的答案,讓電腦去學習辨認,就像在教育小孩一樣,你要它叫媽媽,首先你要告訴它誰是媽媽,所以在辨識行人或是車輛前,你得要先告訴它什麼是行人,什麼是車輛。當我們要辨識圖中的車輛,就要把車輛標示出來,告訴機器,框框內的物件就是車輛,而把行人與車輛標示出來的這個動作,我們稱為標籤化。
 從影像中,標示出我們想辨識的物件,去讓電腦學習,讓它可以替未曾見過的圖像做辨識,並預測這個新圖像可能是什麼,如標示出行人與車輛。(圖/https://alpslabel.wordpress.com/)
從影像中,標示出我們想辨識的物件,去讓電腦學習,讓它可以替未曾見過的圖像做辨識,並預測這個新圖像可能是什麼,如標示出行人與車輛。(圖/https://alpslabel.wordpress.com/)
這些標籤化的影像,其實就是提供電腦我們希望它能夠辨識的物件,提供給電腦去學習,所以若我們想要提高其辨識的準確度,我們則需要大量的標籤化影像,而這些大量標籤化後的影像資料,將成為我們用來訓練類神經網路系統(名詞解釋)的影像資料庫,透過大量影像資料的訓練,讓機器能夠不斷的學習,並透過結果的反饋,也就是告訴機器判斷的結果是否正確,進而修正調整類神經網路上每個神經元的參考權重值,最後機器判斷的結果也將越來越準確。
而為了達到較高的辨識準確率,在影像的辨識系統上,通常會使用深度學習(deep learning),它指的是一種特定的機器學習法——「深度神經網路」,也就是使用較多層的類神經網路(
註1),它的辨識準確率比起其他的機器學習方法要大上很多,深度學習這項現在最熱門的技術,其實並非最近幾年才提出的構想,而是因為過去硬體處理器沒辦法負荷深度學習所帶來龐大的運算量,所以一直以來,很少人真的有辦法去實現這套理論架構,但因為現在的硬體處理器技術與速度都比過去提升很多,也使利用深度學習的影像與聲音的辨識技術得以實現。
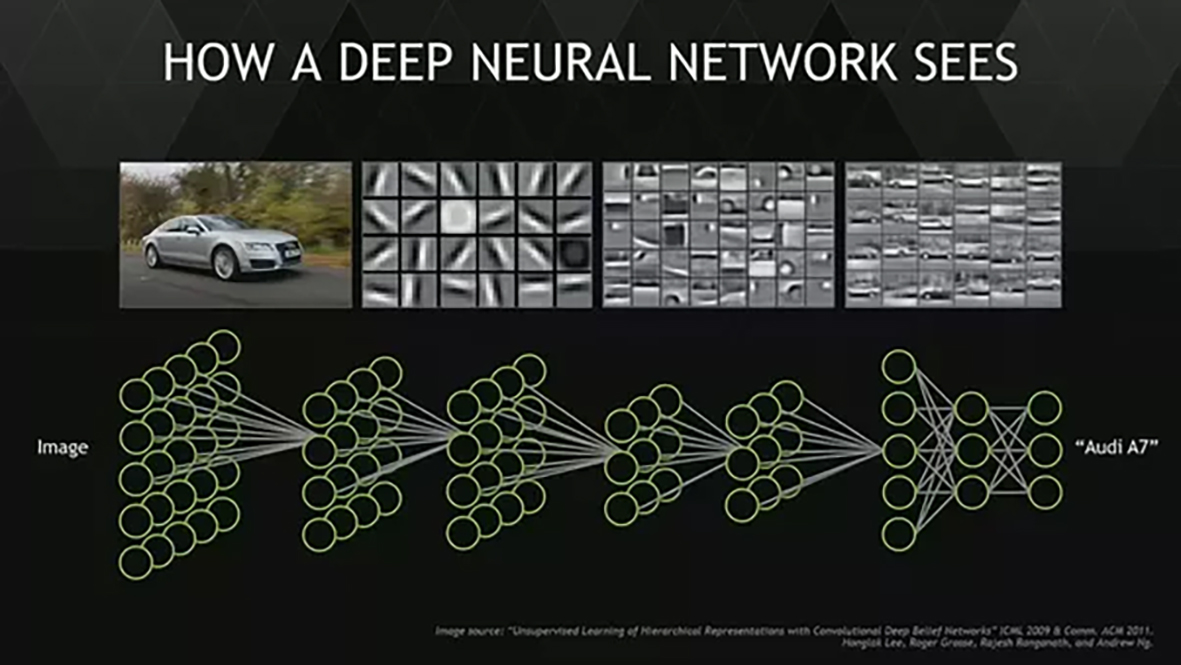 類神經網路是機器學習最重要的部分,當你把圖像資料丟進類神經網路後,經過幾層的特徵值判斷,如圖中,第一層是線條特徵的判斷,第二層則為局部性特徵判斷,如輪胎,車燈,第三層則提升為車輛整體特徵的判斷。最後會得到一個輸出的結果,圖片中的Audi A7就是透過類神經網路判斷出的結果。(圖/https://www.slideshare.net/ShamaneSiriwardhana/introduction-to-convolutioanl-neural-net)
類神經網路是機器學習最重要的部分,當你把圖像資料丟進類神經網路後,經過幾層的特徵值判斷,如圖中,第一層是線條特徵的判斷,第二層則為局部性特徵判斷,如輪胎,車燈,第三層則提升為車輛整體特徵的判斷。最後會得到一個輸出的結果,圖片中的Audi A7就是透過類神經網路判斷出的結果。(圖/https://www.slideshare.net/ShamaneSiriwardhana/introduction-to-convolutioanl-neural-net)
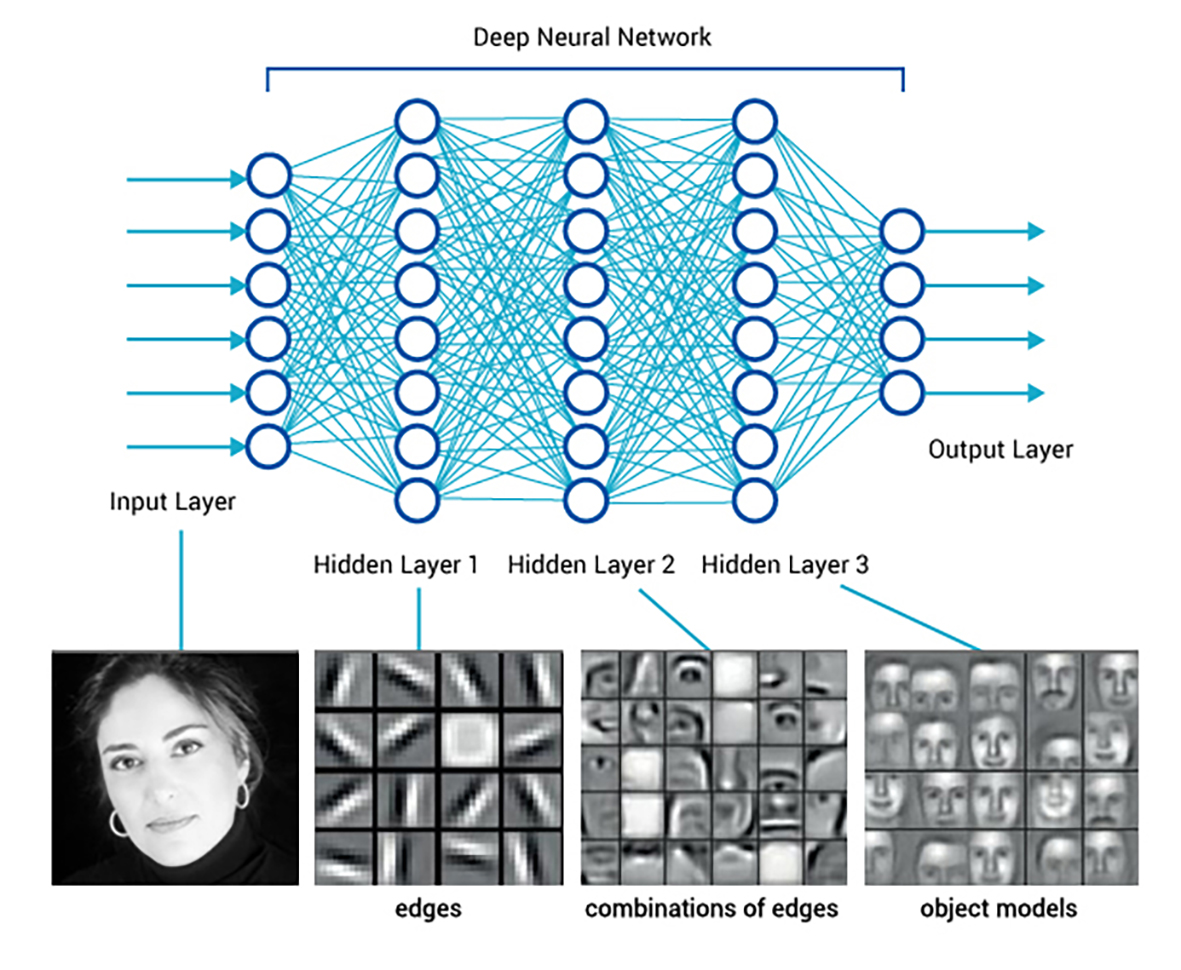 深度學習的人臉辨識範例,同樣需經過幾層的特徵值判斷,第一層是線條特徵的判斷,第二層則為局部性特徵判斷,如眼睛、鼻子等,第三層則提升為整體人臉特徵的判斷。最後會得到一個輸出的結果。(圖/https://case.ntu.edu.tw/blog/?p=26340)
深度學習的人臉辨識範例,同樣需經過幾層的特徵值判斷,第一層是線條特徵的判斷,第二層則為局部性特徵判斷,如眼睛、鼻子等,第三層則提升為整體人臉特徵的判斷。最後會得到一個輸出的結果。(圖/https://case.ntu.edu.tw/blog/?p=26340)
智慧駕駛:更安全的未來近在眼前?
上述為利用機器學習進行圖形辨識的最基本介紹,人工智慧在影像辨識技術上不斷地有所突破,使自駕車能夠利用自動辨識前方障礙物,並做出相對應減速或煞車的動作,以達到安全性的目的,其實,自動駕駛要能夠實現,最重要的還是要能夠保護自身與用路人的安全,雖然再先進的感測裝置都無法保證百分之百準確,但可以期待的是,隨著未來科技不斷地發展與創新,不論是無人駕駛還是輔助駕駛,一定都能讓未來的行車更加安全且有保障。
 財團法人車輛研究測試中心開發的影像辨識系統。(圖/財團法人車輛研究測試中心)
財團法人車輛研究測試中心開發的影像辨識系統。(圖/財團法人車輛研究測試中心)
註1:類神經網路:類神經系統由多個神經元構成,為了模擬人類神經細胞行為,通常設定每一個神經元都是一個「激發函數」,其實就是一個公式;當對神經元輸入一個輸入值(input)後,經過函數的運算、產生一個輸出值(output),這個輸出值會再傳入下一個神經元,成為下一個神經元的輸出值。重複這個動作,從第一層的「特徵向量」作為輸入值,一層層傳下去、直到最後一層輸出預測結果。
