 巨量資料的分析為人類帶來產品的加速生產與決策,取代大量人力所無法解決的困境。(圖片來源 : 工研院/網址:https://www.itri.org.tw/chi/content/publications/contents.aspx?&SiteID=1&MmmID=2000&MSid=707267552246742173)
巨量資料的分析為人類帶來產品的加速生產與決策,取代大量人力所無法解決的困境。(圖片來源 : 工研院/網址:https://www.itri.org.tw/chi/content/publications/contents.aspx?&SiteID=1&MmmID=2000&MSid=707267552246742173)
你知道嗎,當你使用手機或是電腦來閱讀文章、利用通訊軟體和朋友聊天、從網頁中查找各種事物,甚至是從網路進行拍賣或購物的同時,你可能已經成為產生數據的一份子了。眾多資料從世界各個角落同時產生,例如:影片、音樂和個人網站等,這些多樣化的資料型態以及符合快速傳輸的需求,最後集結而成現在被廣泛熱烈討論的大數據。然而,到底應該如何儲存與處理如此龐大的資料量呢?
雲端資料庫的出現為龐大且難以處理的複雜資料開闢新的道路,而有著黃色小象標誌的Hadoop即是鋪陳新道路的其中一項有效的雲端資料儲存以及運算的環境。想像你的筆電中擁有數十億的影片要儲存卻空間不足,這時,雲端資料庫提供一個足夠大的平台解決有限的儲存空間,此外還具有處理以及分析資料的功能,換言之,也就是我們時常聽說的雲端平台。而Hadoop即是眾多雲端平台其中之一,是一套含有開放給大眾使用與修改工具的框架(即為開放原始碼框架),且是完全免費的軟體,因此深受企業歡迎。
 圖一:雲端資料庫Hadoop的組成分層。(圖片來源:Tutorialspoint/網址:https://www.tutorialspoint.com//hadoop/hadoop_quick_guide.htm)
圖一:雲端資料庫Hadoop的組成分層。(圖片來源:Tutorialspoint/網址:https://www.tutorialspoint.com//hadoop/hadoop_quick_guide.htm)
透過黃色小象Hadoop為例,讓我們來進一步了解雲端資料庫是如何儲存並處理龐大的資料吧!
Hadoop的架構中主要分為圖一中的四個區塊:
一、Hadoop Common Utilities
以晚餐食材的購買為例,車子是搭載大量食材與購買者的一項工具,然而,車子需要燃油、輪子、方向盤等才得以駕駛,同理,Hadoop也需要透過各種元件組成,而這些能夠架構出Hadoop的所有元件皆包含於Hadoop Common Utilities中,例如:高階程式語言以及程式語言庫等。
二、Hadoop YARN Framework
當我們為了晚餐開車出門去購買食材時,會思考要先採買哪些食物,或是以優先休息的店家開始採買。而YARN即是如此,為所有等待中的資料進行運算的順序分派,藉以提升工作效率。此外,還會針對來自不同機器的資源進行管理,也稱作叢集資源管理。
三、Hadoop HDF(Hadoop Distributed File System,分散式檔案系統)
完成食材購買後,所有材料都會被儲藏於冰箱中,其中,會依據不同類別分別放於不同隔層中保存,當準備要做菜時再從相對應的隔層中拿出需要的食材。HDFS即是一個大冰箱的概念,一套使用數以千計的節點來存放資料的系統,而食材與隔層分別為資料與節點。
四、Hadoop MapReduce
此時,家裡來了大批的客人,為了讓大家都吃到熱騰騰的晚餐,媽媽決定請家人們一起幫忙準備,一些人被分配切菜,其餘則是洗菜,最後媽媽完成炒菜與調味。而MapReduce則是透過類似的多節點並行處理(如圖二),如同分配任務一般,同時進行運算,大幅降低巨量資料所需的時間,最後統一進行分析或決策,是一套由Google發表具平行運算架構的方法。
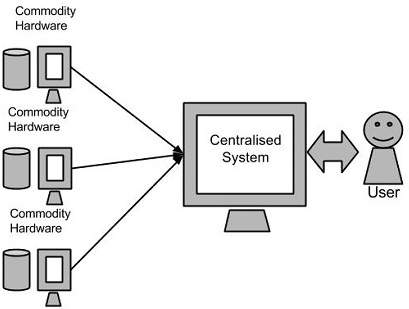 圖二:分配任務給予各個節點小分隊。(圖片來源:Tutorialspoint/網址:https://www.tutorialspoint.com//hadoop/hadoop_quick_guide.htm)
圖二:分配任務給予各個節點小分隊。(圖片來源:Tutorialspoint/網址:https://www.tutorialspoint.com//hadoop/hadoop_quick_guide.htm)
綜合上述,黃色小象有效提供存放與處理大數據的方法,目前已經被認為是主流的開放式雲端資料處理平台。然而,Hadoop仍舊只是一個較為簡單的框架,無法處理更為複雜的運算或是排列與儲存。因此,在各種動物以及人類跟隨加入之下,更完整的資料儲存與處理的生態圈便形成(如圖三),除了有黃色小象Hadoop作為雲端平台,也加入如馴獸師般的開放原始碼Mahout,提供目前熱門的機器學習的程式庫或其他演算法程式庫,加速資料處理的時間,避免黃色小象在相同道路上打轉過久,能夠以最短的時間達到目的地。如此一來以黃色小象為首的資料處理生態圈建立,這些附加於原始Hadoop基礎之上的技術,增加了雲端資料庫處理資料的彈性以及完整性,使大家能更順暢的透過網路進行線上聊天或查詢資料等用途。
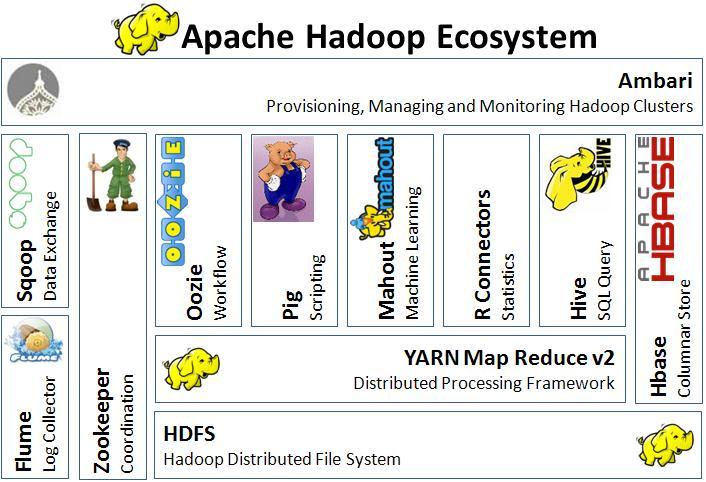 圖三:雲端資料庫Hadoop生態圈。(圖片來源:Agroknow Blog/網址:http://blog.agroknow.com/?p=3810)
圖三:雲端資料庫Hadoop生態圈。(圖片來源:Agroknow Blog/網址:http://blog.agroknow.com/?p=3810)
副總編輯:國立中山大學資訊工程學系 陳坤志教授
總編輯:國立中山大學資訊工程學系 黃英哲教授
(本文由科技部補助「
新媒體科普傳播實作計畫」執行團隊撰稿)
