 除了英文、中文等較多人使用的語言,李宏毅也希望讓機器學會「冷門」的語言。(圖/fatcat11繪)
除了英文、中文等較多人使用的語言,李宏毅也希望讓機器學會「冷門」的語言。(圖/fatcat11繪)
在人與人用語言交談的過程中,我們先聽懂了對方說的每一個字,然後組合理解整個文句(例如:今天天氣如何),接著提供合理的回應(今天是晴天)。李宏毅說:「這些處理過程中的每一步,都可以用『機器學習』(machine learning)的技術來讓機器學會。」機器學習就是讓機器自己尋找可以輸出正確結果的函式,例如語音辨識的過程,就是讓機器聽一段語音,並輸出一段相對應的文字。「只是這個函式的內容非常非常複雜,沒有人有能力把這個數學式寫出來。」而讓機器自己找出這個函式的方法,就是提供它大量的訓練資料,例如上千個小時的語音訊號與對應的文字,讓機器歸納出函式來。
深度學習讓機器學會語音辨識
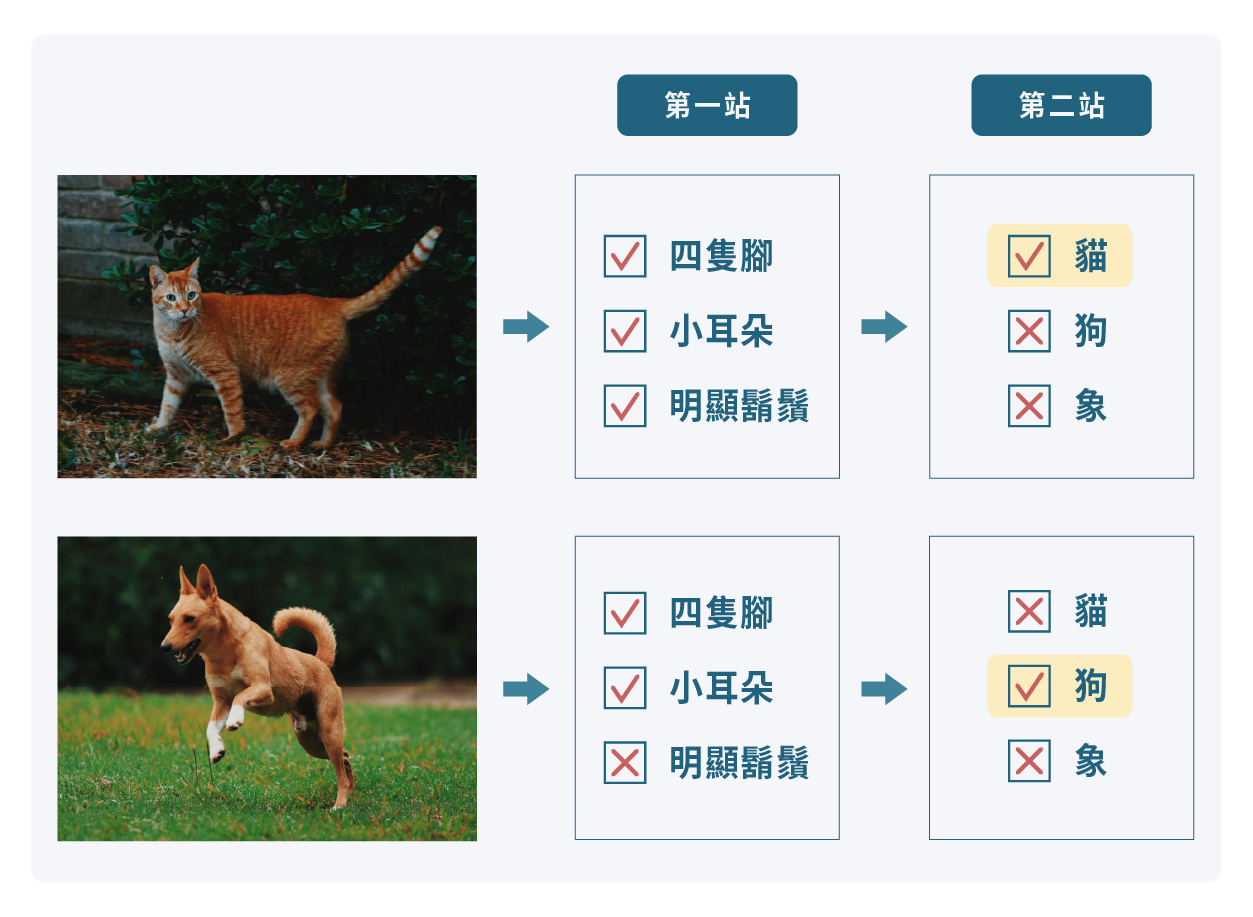
當機器要學習語音辨識或影像辨識時,「深度學習」(deep learning)是近年成果最佳因而最受重視的技術。深度學習的過程會把問題模組化,也就是拆解成許多小塊,李宏毅形容深度學習「就像是一條生產線,上面有很多站,訊號來到每一個站,都只會做一個簡單的判斷,但把這些簡單判斷的結果集合起來,就能讓機器完成複雜的事情。」
<
舉例來說,如果要辨識圖片裡是什麼動物,第一站可能負責偵測圖片裡是否出現鬍鬚、斑紋、四隻腳等特徵,第二站再根據第一站的結果判斷。如果第一站的偵測能力很好,第二站也不需太多訓練資料就能判斷。 (圖/沈佩泠繪,資料來源:李宏毅)在全世界的語音辨識技術上,利用深度學習的技術,已經可以讓中文、英文等語言達到很好的正確率,坊間也早有如Siri、Google語音助理等科技。然而李宏毅希望機器學習語音辨識能更廣泛應用在更多語言上,因為「多數人講的都是少數人的語言。」李宏毅說:「如果我們去掉最多人講的六種語言,剩下的超過一半的人口講的,都是第六名以外的語言。」
生成器與鑑別器的較勁
困難的是,這些比較「冷門」的語言,不像中文或英文的語音訊號與文字都可以兩兩互相對應,也就是不見得有「成對」的資料,所以要收集大量的資料來訓練機器並不容易。因此,李宏毅使用「生成式對抗網路」的技術,這個技術只用到少量的資料,而且其中甚至是沒有成對資料的。也就是說,李宏毅讓機器聽一大堆語音訊號,並閱讀一大堆文字,這些語音與閱讀的文字不同來源、毫無關聯,「這就好像機器在日常生活中聽大家講話,但我們沒有告訴它我們在講什麼,然後它自己去閱讀一大堆文章,也沒有人告訴它文章的內容是什麼,但最後它自己學會了這個語言。」李宏毅解釋。
這聽起來很神奇,其中的奧祕就在於「生成式對抗網路」中,包含了「生成器」與「鑑別器」這兩個角色。生成器就是語音辨識系統,輸入語音訊號後,它會輸出一段文字。另一方面,李宏毅讓鑑別器閱讀大量文字,這些文字和輸入生成器的語音訊號完全沒有關聯。而鑑別器的任務,則是判斷一個句子是人寫的還是機器產生出來的。接下來,生成器的目標就是產生出如同人寫的句子,讓鑑別器分辨不出來。
生成器雖然不知道語音訊號在講什麼,但它可以將類似的訊號片段找出來,這些片段對應到的文字應該相同。生成器會先找出哪些聲音訊號是反覆出現的,並且編號,如此一來,一段文句就會變成一連串編號組成的「神秘文字」,接下來,機器再推測每一個編號對應的文字,把這段神秘文字組成人類語言的句子。然後將這個句子交由鑑別器鑑別,如果不夠像人類寫出的句子,就重新推測編號對應的文字,直到生成的句子通過考驗為止。
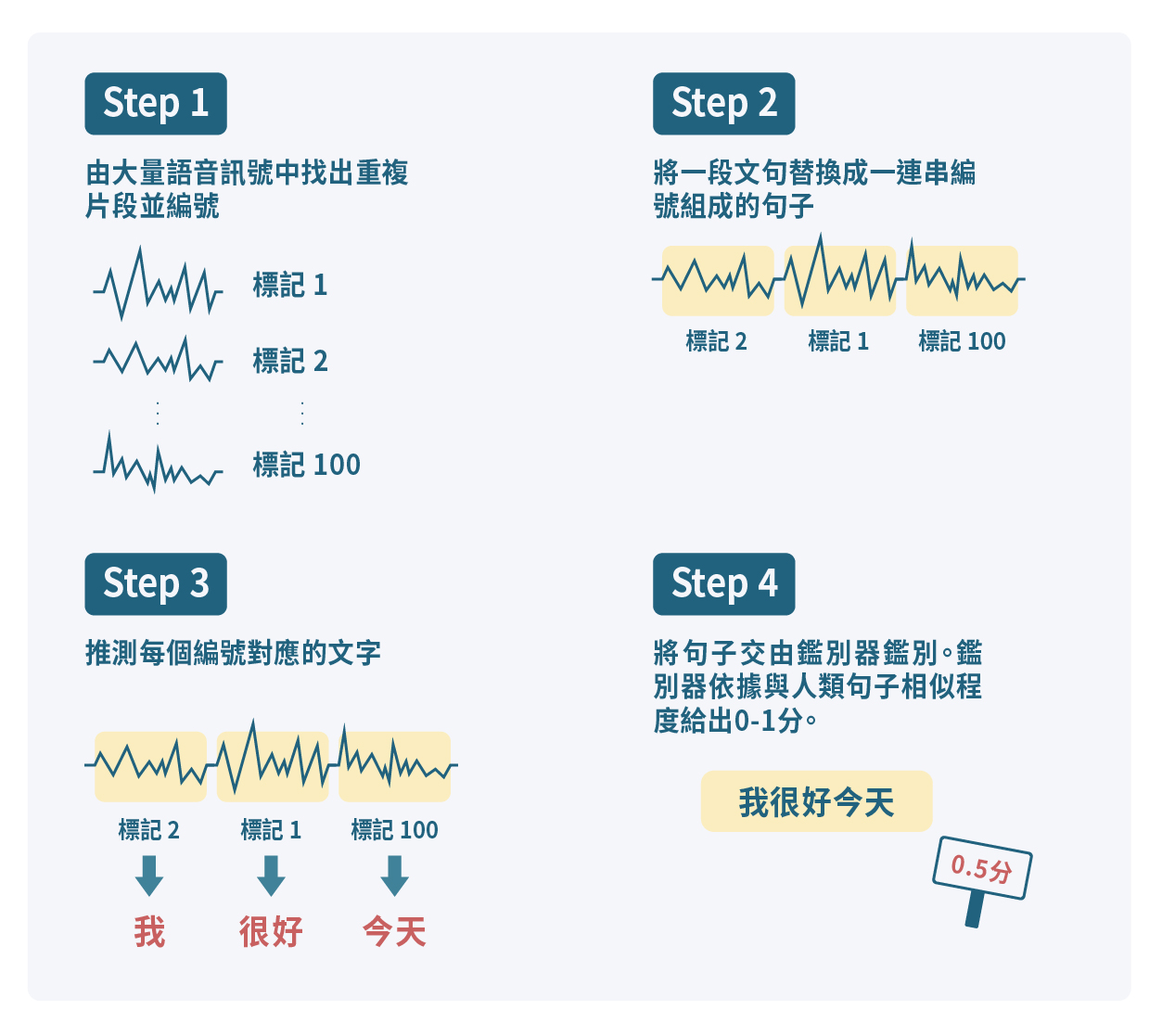 生成器會把反覆出現的聲音訊號編號,推測每一個編號對應的文字、進行標記,然後組成句子交由鑑別器鑑別;如果不夠像人類寫出的句子,就重新推測編號對應的文字。(圖/沈佩泠繪,資料來源:郭雅欣)
生成器會把反覆出現的聲音訊號編號,推測每一個編號對應的文字、進行標記,然後組成句子交由鑑別器鑑別;如果不夠像人類寫出的句子,就重新推測編號對應的文字。(圖/沈佩泠繪,資料來源:郭雅欣)
「我們第一次嘗試利用生成式對抗網路來訓練機器時,錯誤率超過60%,雖然聽起來很高,但當時我們是非常振奮的!因為這證明了這個方法真的可以讓機器學到東西。」而經過不斷改進,目前錯誤率已經下降到33%左右。相較於過往使用大量成對資料訓練機器的「督導式學習」,這種「對抗式學習」的錯誤率雖然還是比較高,不過李宏毅說:「在30年前,督導式機器學習剛剛被用在語音辨識上時,在同樣的語料庫上錯誤率也大約是33%;我們可以預期或許30年後,非督導式學習就可以趕上目前語音辨識的成果。」到時候,不需要人類介入教學,機器自己就能學會新的語言!
除了對抗式學習外,李宏毅也嘗試著讓機器自己尋找有效率的學習語言方式,也就是更好的演算法,這種讓機器自己學習如何學習的方式,稱為元學習(meta-learning)。「目前正確率比較高的語音辨識系統甚至經過幾十萬個小時的語音訊號訓練,這比多數人類的一生可以聽到的語音訊號還要多。人類不需要聽那麼多就可以學會語言,這代表很可能還有更好的演算法存在。」李宏毅說。
如果可以像李宏毅所期待的,機器能夠學習所有跟處理人類語言有關的技能,不論在語音辨識、語言翻譯、語言理解等技術上,都獲得長足的進展,或許到時候,機器能替人類構築一個溝通無礙的世界,為人工智慧帶來新的想像。
審閱:李宏毅教授

 姓名標示─非商業性─禁止改作
姓名標示─非商業性─禁止改作