
115/03/31
算力不是唯一指標!解析「專屬 AI 晶片」如何用高效率驅動未來
寒波|
科技大觀園特約編輯
 (圖/Jannes Glas拍攝,Unsplash)
(圖/Jannes Glas拍攝,Unsplash)
「請點擊下方包含「紅綠燈」的圖片。」
當我們在進行帳號驗證時,登入平台總是發揮想像力,讓你證明自己是一個人類,甚至逗趣的出現「我不是機器人」的勾選字樣。
而試著「找出紅綠燈」將不同的物件進行辨識,正是電腦視覺(computer vision)的拿手好戲。因為是「看」的科學,我們首先就需要讓電腦有眼睛(鏡頭),而且有素材能加以分析。
 「請點選圖中包含紅綠燈的部分。」若要成功登入,必須選對格子(紅格處)。(圖/imgflip)
「請點選圖中包含紅綠燈的部分。」若要成功登入,必須選對格子(紅格處)。(圖/imgflip)視訊畫面內插:資源消耗與觀賞感受的平衡點
這樣針對畫面的劃分,也能分為「語意分割」、「實例分割」兩種,前者能將不同物件區分,後者則是另外一種昇華的應用,它能將畫面中的物件如同「去背」一樣的偵測出來,並進行標註。
 物件偵測(A)、語意分割(B)、實例分割(C)。(圖/IEEE Xplore)
物件偵測(A)、語意分割(B)、實例分割(C)。(圖/IEEE Xplore)
當我們看著一張照片時,裡頭的畫面是靜止不動的,但如果有兩張具相關性的照片,讓我們來回翻動,就會感覺照片中的人事物有在移動的感覺,雖然會有一種卡頓感,但這也能算是一種每秒拍攝影格率(frame rate)很低的動態影像。如果我們希望不要有卡頓感,就得讓影格率保持在10~12張/秒,如此一來,大腦就會判定其為一個連續的動態影像。
因此拍攝影格率與觀看體驗,是一個正相關的存在,然而提高拍攝影格率,也會造成該影片的檔案容量變大、耗費的電力提高。為了彌補這個缺點,科學家便發明了這個方法:視訊畫面內插。內插的原理是:假設以下的18個白色空格,是一張一張的畫面,他們播放的速率相同,而空格從開始到結束,共花三秒的時間。
□□□□□□□□□□□□□□□□□□
花了三秒鐘,因此拍攝影格率為6張/秒,剛剛提到,低於10就會給人腦不連貫的感覺。
科學家希望不再增加畫面,以避免耗費過多資源,但又希望讓畫面影格率提升,因此提出了「視訊畫面內插」,也就是透過電腦判定兩個畫面之間的差異,進而演算出畫面中物件的移動方式,並將演算出的新畫面插入畫面之間。
內插完成後,影格基本上會變成下方這樣,白色為原畫面,而黑色為新插入的畫面。
□■□■□■□■□■□■□■□■□■□■□■□■□■□■□■□■□■□
如此一來,三秒鐘的時間變有35個影格,因此影格率提升為11.3/秒,人腦就能感受到順暢的畫面了!
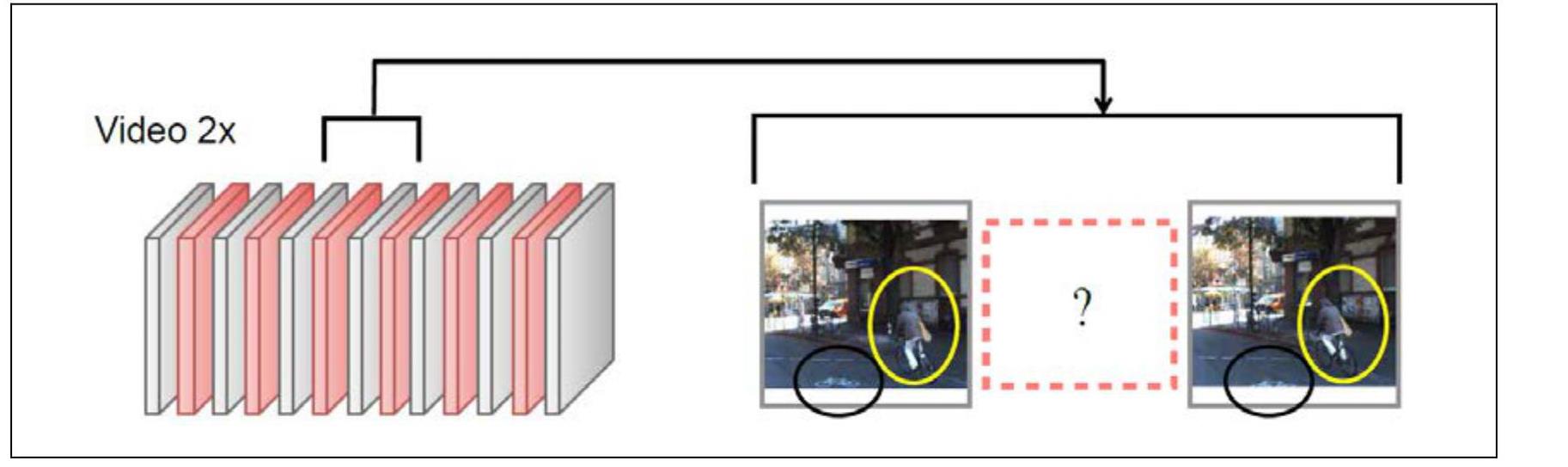 畫面內差的原理,就是運算出兩個畫面之間的畫面,原理如下。(圖/交通大學教授林彥宇提供)
畫面內差的原理,就是運算出兩個畫面之間的畫面,原理如下。(圖/交通大學教授林彥宇提供)而目前常用的方式,是讓電腦透過深度學習的方式來完成內插,例如Deep Voxel Flow (DVF),但這種內插的方法也存在著缺點,若畫面中存在快速移動的物件(如投擲出去的球、奔跑的腳),可能造成畫面過於模糊,或是失真等問題。
 原始的三張影格。(圖/交通大林彥宇教授提供)
原始的三張影格。(圖/交通大林彥宇教授提供) 使用DVF完成的內插,畫面過於模糊(over-smoothed interpolation)、失真(artifact),全因為畫面中的物件正在快速移動。(圖/交通大學教授林彥宇提供)
使用DVF完成的內插,畫面過於模糊(over-smoothed interpolation)、失真(artifact),全因為畫面中的物件正在快速移動。(圖/交通大學教授林彥宇提供)
正當學界對這個問題困擾之際,交通大學資工系教授林彥宇與台灣大學資工系教授莊永裕的聯合研究團隊想出了三個對策。
首先,高品質的內插畫面可以再「回插」原畫面,以上面黑白相間的畫面為例,我們不只可以從白色影格(奇數)推算黑色影格(偶數),也能依樣畫葫蘆,用黑色再推敲出白色,如此我們不只可以內插出偶數畫面,也能以偶數畫面還原奇數畫面,如此便能大幅降低畫面的失真。
再來是將畫面之間的變化,以線性做為假設呈現,其實畫面之間並非線性,而是一格一格快速的轉變,因此畫面中的物件位置,若要以線來呈現他們移動的情形,那這條線應該是由許多點連接的「鋸齒狀」。雖然在有加速度移動的情況下,這個假設不成立,但因為這些鋸齒間隔很短,不會造成太大的誤差,因此若以「一條線」的方式假設,有助於預防讓電腦內插出不一致的畫面,降低內插畫面的誤差。
最後,他們也使用「邊緣影像」協助內插,邊緣影像的特性在於,它含有物件與背景間,以及物件與物件間的邊界資訊。如此便可利用這項重要資訊,來預測內插畫面中邊緣的分佈,更能避免內插出過於模糊的畫面。
 使用研究團隊提出的解方進行運算,插入的畫面清楚許多。(圖/交通大學教授林彥宇提供)
使用研究團隊提出的解方進行運算,插入的畫面清楚許多。(圖/交通大學教授林彥宇提供)往「零誤差」邁進的電腦視覺
從電腦視覺到視訊畫面內插,雖然仍不能達成零誤差的演算,但其實這項科學領域已經走得相當遠。人類的眼睛、大腦都是經由幾百萬年的演化,才能到達如此精密的境界,但科學家卻能透過相對極短的時間,將「電腦的眼睛」強化至此,甚至有過之而無不及,已是非常厲害的成就。
在資訊爆炸的時代,視訊愈來愈普及,現代社會已經不能沒有「視訊畫面」了,因此這項研究成果對於在資源消耗與視訊畫面呈現之間,找到一個雙贏的平衡點,可說是邁進了一大步
 姓名標示─非商業性─禁止改作
姓名標示─非商業性─禁止改作
本著作係採用 創用 CC 姓名標示─非商業性─禁止改作 3.0 台灣 授權條款 授權.
本授權條款允許使用者重製、散布、傳輸著作,但不得為商業目的之使用,亦不得修改該著作。 使用時必須按照著作人指定的方式表彰其姓名。
閱讀授權標章或
授權條款法律文字。