你想玩VR版的英雄聯盟嗎?不是簡單地用VR眼鏡來看手機的畫面,而是像動漫刀劍神域那樣,將玩家真正帶入虛擬世界當中,以第一人稱視角展開,360度全方位無死角。如果能夠像這樣身歷其境的打電動,一定很痛快吧!
 英雄聯盟(圖/截圖自官方Youtube頻道)
英雄聯盟(圖/截圖自官方Youtube頻道)
但360度畫面也有一個小缺點,在初學階段,做為新手的我們太容易死啦。這是因為原本我們使用的手機屏幕畫面很單一,我們不需要特別注意便能判斷敵人的方向,以及前進的路線。但360度的畫面對路痴顯然不是一件好事,並且過於豐富的內容也很容易讓人分神,找不到重點。
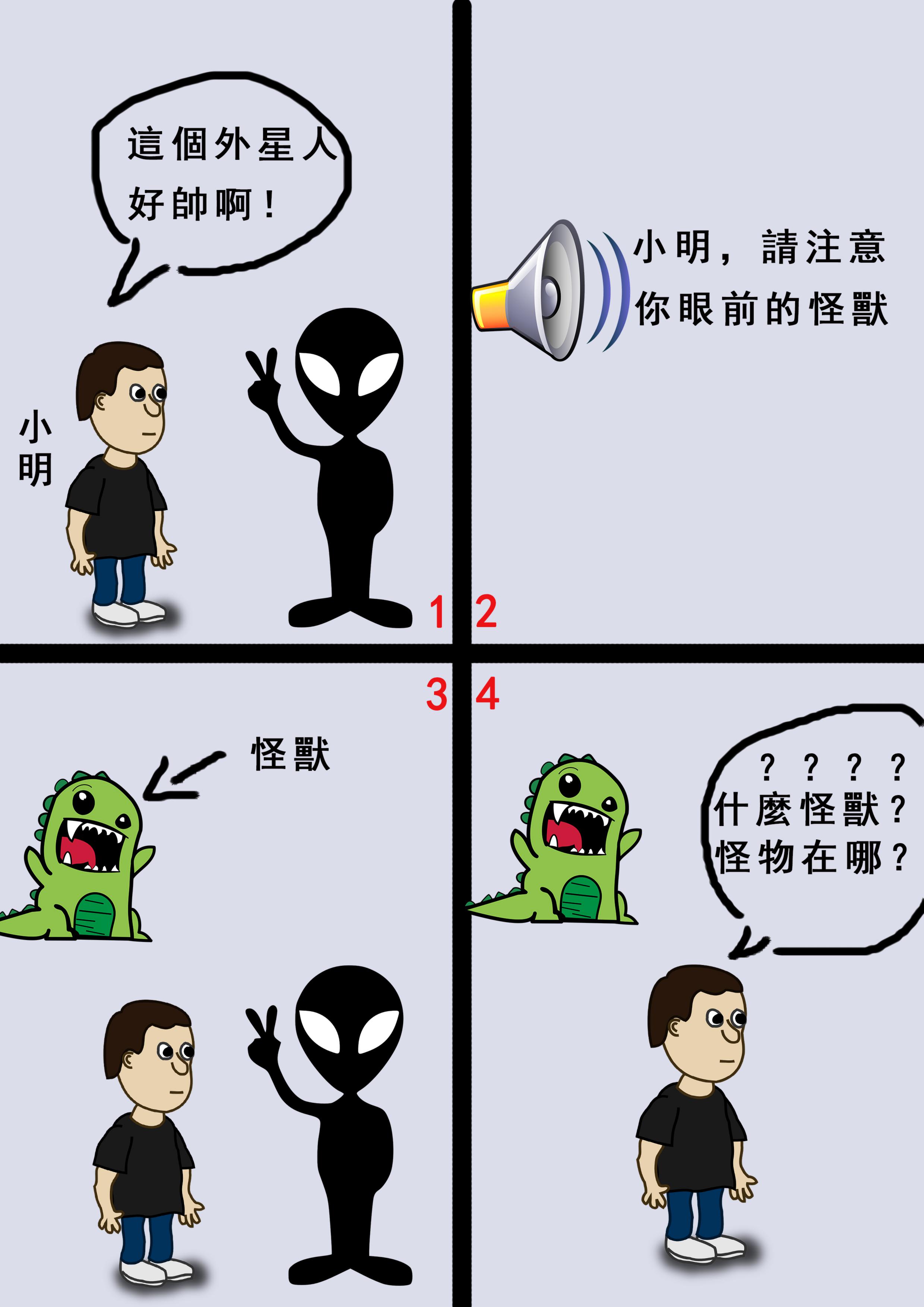 在360畫面中,玩家很容易失去焦點,圖中的小明因為只關注於眼前外星人,而找不到廣播中所說的怪獸。(圖/連俊翔提供)
在360畫面中,玩家很容易失去焦點,圖中的小明因為只關注於眼前外星人,而找不到廣播中所說的怪獸。(圖/連俊翔提供)
那麼我們該怎麼解決這一問題呢?答案就是新手訓練區的畫面與解說的自動匹配功能!
自動匹配功能:將特定畫面和文字畫上等號
什麼是畫面與解說的自動匹配功能?簡單來說,就是我們所看見的畫面能夠依據解說的內容自動轉換。比如說,解說告訴我們「敵人來襲」,那麼畫面便會自動轉向有敵人向我們進攻的那一面;或者解說提醒「前方有掉落的鑽石」,那麼畫面便自動轉向有鑽石掉落的那一面。
畫面與解說的自動匹配能夠幫助新手在剛接觸這款遊戲時減低難度,幫助玩家更好地理解該如何操作VR版的英雄聯盟。
自動匹配功能背後的原理並不複雜,我們需要做的只是讓電腦知道這個畫面與這段文字是同一個意思,也就是說,將這個畫面和文字畫上等號。
 小狗在人類的眼中是一種可愛的生物,但是在電腦中,它只是一串編碼,我們為電腦建造一個數據庫,裡面是各個事物所對應的編碼,例如貓咪對應的便是A1001,漢堡是A1002,小狗是A1003。(圖/連俊翔提供)
小狗在人類的眼中是一種可愛的生物,但是在電腦中,它只是一串編碼,我們為電腦建造一個數據庫,裡面是各個事物所對應的編碼,例如貓咪對應的便是A1001,漢堡是A1002,小狗是A1003。(圖/連俊翔提供)
這其實便是翻譯蒟蒻呀,因為文字和畫面對於電腦而言,便像是我們在學日文與英文。那麼我們如何將一個英文單詞對應到日文中呢?對,通過中文這個橋樑,我們會將這個英文單詞翻譯成中文,然後再去找同樣是這個意思的日文單詞。
對於電腦而言,便是分別將畫面和文字進行編碼,對於文字,我們使用「循環神經網路」(Recurrent Neural Networks, RNN),將文字丟入RNN中,它便會將這段文字編譯為一串獨一無二的編碼。
而在影像部分,因為影像其實是由一張張圖片疊加而成,所以在影像的編碼上,我們使用能將圖片翻譯成編碼的「卷積神經網路」(Convolutional Neural Networks, CNN)。我們將影像丟入CNN中,得到對於這段影像的編碼。
例如在圖三中,我們將地球的圖片編碼為A3001,將「地球」這個文字也編碼為A3001,那麼對於電腦而言,這兩者便是相等的,但我們輸入文字「地球」時,電腦就會自動匹配到它的圖片啦。
又例如將「敵人來襲」這個畫面編碼為“010111”,並將這個一段文字也編碼為“010111”,於是這段文字和影片對於電腦而言,便是同一個東西。因此電腦在接收「敵人來襲」這個文字時,其實接收到的便是“010111”這段編碼,就會自動匹配到同樣是“010111”的這段影片。
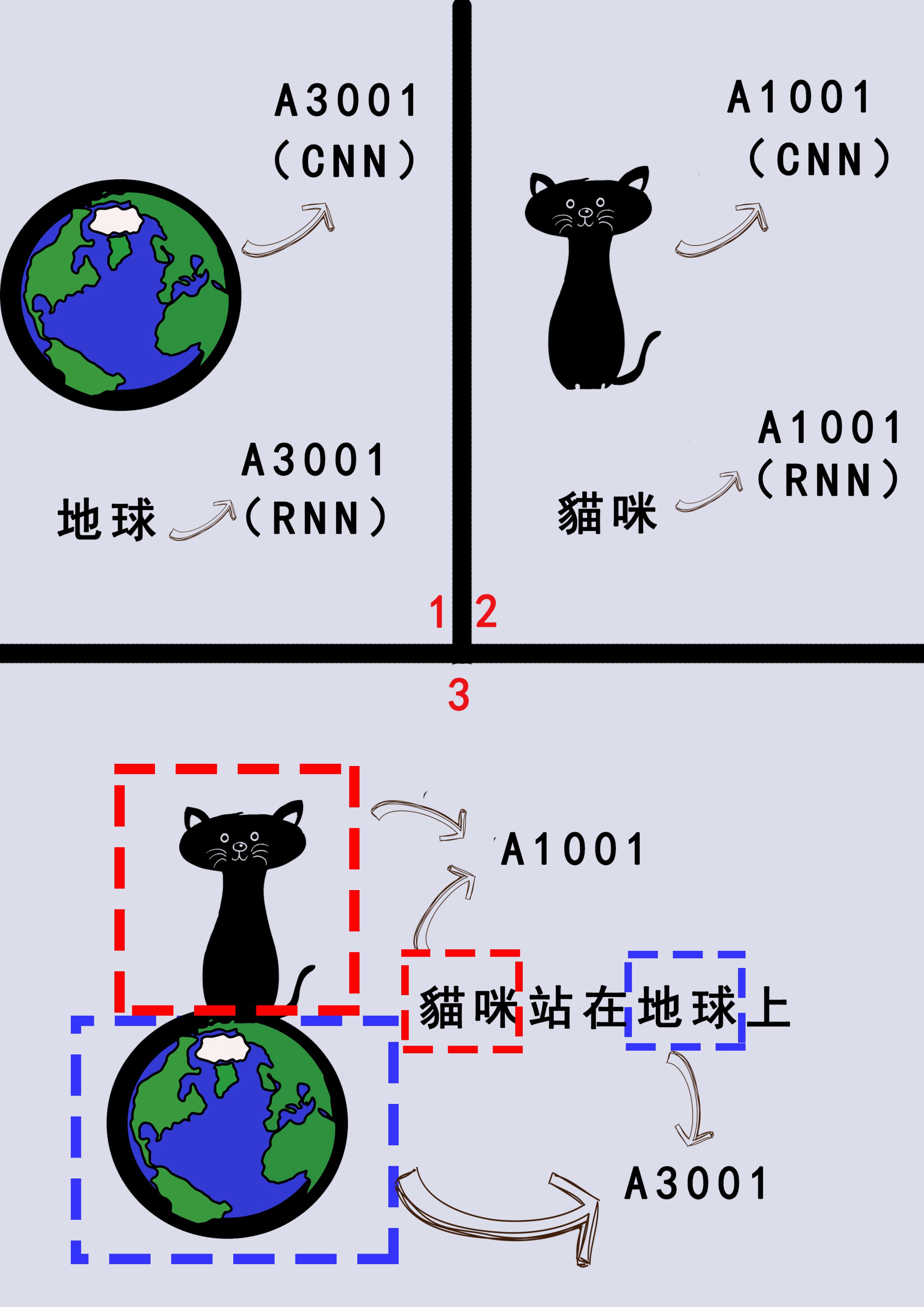 我們通過CNN和RNN分別對圖片和文字進行處理,將貓咪、地球各自編碼後,電腦便能將相同編碼的事物進行串連,把「貓咪站在地球上」這句話的相應畫面正確的呈現出來。(圖/連俊翔提供)
我們通過CNN和RNN分別對圖片和文字進行處理,將貓咪、地球各自編碼後,電腦便能將相同編碼的事物進行串連,把「貓咪站在地球上」這句話的相應畫面正確的呈現出來。(圖/連俊翔提供)
電腦也需要不同口味的翻譯蒟蒻
在編碼的過程中,面對文字和影像,電腦也需要不同口味的翻譯蒟蒻。這便像是我們在查找英文單詞和日文單詞時,會使用不同的字典一樣,電腦也需要不同的演算法來對文字和影像進行編碼。
讓電腦吃下這兩塊不同口味的翻譯蒟蒻所得到的編碼,就能夠用來讀取影像和文字。因此在新手訓練區中,當解說提到「敵人來襲」時,玩家便會自動匹配到相關的畫面,減低因為找不到敵人而失敗的風險。
這便是自動匹配功能背後的原理,你明白了嗎?
參考資料
1. Christianson, D. B.; Anderson, S. E.; He, L.-w.; Salesin, D. H.; Weld, D. S.; and Cohen, M. F. 1996. Declarative camera control for automatic cinematography. In AAAI.
2. Chen, J.; Le, H. M.; Carr, P.; Yue, Y.; and Little, J. J. 2016. Learning online smooth predictors for realtime camera planning using recurrent decision trees. In CVPR.
3. Su, Y.-C.; Jayaraman, D.; and Grauman, K. 2016. Pano2vid: Automatic cinematography for watching 360◦ videos. In ACCV.
4. Li, Z.; Tao, R.; Gavves, E.; Snoek, C. G. M.; and Smeulders, A. W. 2017. Tracking by natural language specification. In CVPR.

 姓名標示─非商業性─禁止改作
姓名標示─非商業性─禁止改作